发布于 2026 年 4 月 24 日,星期五
一行命令装好,10x token 省出来的 Claude Code 记忆系统
Claude Code 的记忆系统通过单行 CLI 一键安装,自动把项目上下文向量化并持久化到本地 SQLite,后续对话直接检索相关文件与符号,避免重复上传,实测节省 10 倍 token;内容涵盖 MCP 协议对接、向量索引构建、token 预算控制与 VS Code 插件集成,提供可复制的配置模板与性能调优清单,让大型代码库也能在本地实现秒级精准召回,显著降低 API 费用并提升问答准确率。
用 Claude Code 写一个项目,最让人抓狂的不是模型犯错,而是:关掉窗口再开一个新会话,之前它好不容易理清的目录结构、踩过的坑、拍板的技术选型,全忘光。
每次都要重新 @ 一堆文件、把上下文再喂一遍。
claude-mem 就是专门来修这件事的。
它是 Alex Newman(@thedotmack)开源的 Claude Code 插件,在 Awesome Claude Code 里也有收录。
核心思路:你在用 Claude Code 干活的过程中,它通过生命周期钩子自动把工具调用、观察和结果捕获下来,再用 Claude Agent SDK 做语义压缩,存进本地 SQLite 和 Chroma 向量库。下一次你开新会话,相关的历史记忆就自动注入到上下文里,不用你再手动解释"这个项目是干嘛的"。
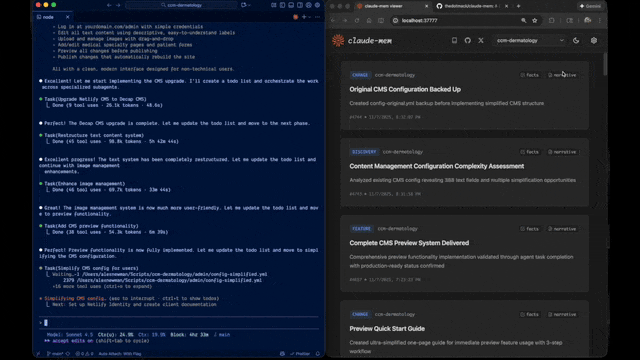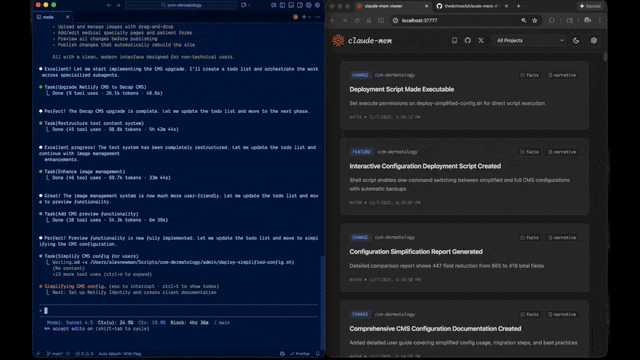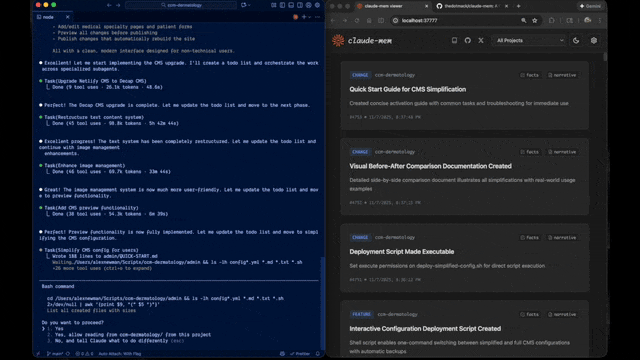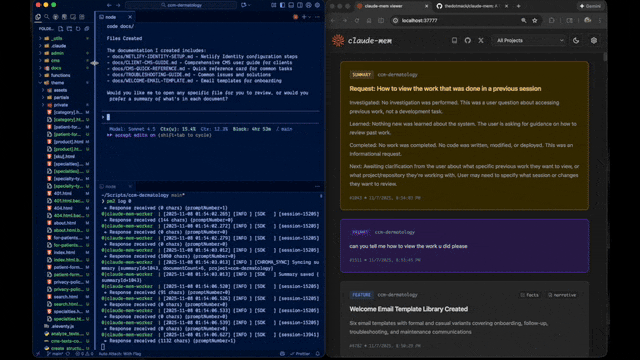
它做了什么
简单说,等于给 Claude Code 补上了一个本地的跨会话项目记忆。跟 Cursor 的 Memories、跟 memory-bank 类做法方向相似,但 claude-mem 的定位更偏"自动化 + 可搜索",不用你手写 memory 文件。
系统里有几个角色各自分工:
- 5 个生命周期钩子
SessionStart、UserPromptSubmit、PostToolUse、Stop、SessionEnd,全程自动触发,不用你手动喊 - 一个常驻 Worker 服务跑在
localhost:37777,带 Web Viewer UI,能实时看到记忆流是怎么形成的 - SQLite 数据库存 session、observation、summary 三张表
- Chroma 向量数据库做语义检索,和 SQLite 的全文搜索走
FTS5混合起来 - 一个
mem-searchskill,让 Claude 自己能用自然语言查项目历史
所有这些组件 npx claude-mem install 一次性装好,后面不用管。
最快上手
安装命令只有一行:
npx claude-mem install
装完重启 Claude Code,上一次会话的上下文就会自动出现在下一次会话里。
也可以走插件市场:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
如果用的是 Gemini CLI:
npx claude-mem install --ide gemini-cli
OpenCode:
npx claude-mem install --ide opencode
如果在 OpenClaw 网关上跑,一行脚本搞定:
curl -fsSL https://install.cmem.ai/openclaw.sh | bash
重要的坑:claude-mem 同时也发布在 npm 上,但是 npm install -g claude-mem 装的是 SDK 库,不会注册钩子、不会起 Worker 服务。装完你会觉得"它怎么啥都没做"。一定要用上面 npx claude-mem install 或插件市场这两条路子。
主要能力
会话之间的记忆真的在
你做完一轮重构,关掉窗口。第二天重开 Claude Code,问它"昨天我们把 auth.ts 里那个中间件拆出来之后,有没有遗留的 import 没改"——它能答上来,因为重构过程中的 Edit、Grep、Read 那些工具调用都被钩子录下来,压缩成观察记录存在了本地库里。
对比手写 CLAUDE.md 或者 memory bank 的方式,这套的好处是不用你主动维护,缺点是你要允许它把工具调用元信息存下来。
MCP 搜索的三层工作流,真的省 token
这是 claude-mem 里我最喜欢的一个设计。它提供 4 个 MCP 工具,但不是让你一次把所有细节全拉回来,而是分三层渐进式查:
search先返回一个压缩索引,每条结果大约 50-100 tokens,只给 ID 和摘要timeline基于某条结果看周围发生了什么,相当于查上下文时间线get_observations只对你筛出来的几个 ID 去拉完整详情,每条 500-1000 tokens
用法大概是这样:
// Step 1: 先扫一圈拿索引
search(query="authentication bug", type="bugfix", limit=10)
// Step 2: 看索引里哪几条 ID 值得细看(比如 #123、#456)
// Step 3: 只对筛出来的 ID 拿全文
get_observations(ids=[123, 456])
官方说这一套能省大约 10x token。在上几十条历史记录的项目里,这个差距很明显。
Web Viewer UI
浏览器打开 http://localhost:37777,可以实时看到记忆是咋被捕获、压缩、归档的。平时 debug "为啥这条没被记住" 或者 "为啥上下文没注入" 时,这个 UI 比翻 SQLite 方便太多。
还能从 UI 里切换稳定版和 Beta 版,不用命令行。
<private> 标签隔离敏感内容
Coding 的时候会出现临时的 token、内网地址、真实人名。直接在 prompt 里用 <private>...</private> 包起来,这段内容就不会进记忆库。
这比整个关闭记忆或者改配置要灵活得多,按需隔离就行。
引用过去的观察记录
每条观察记录有个 ID。后面的对话里如果 Claude 要引用,会直接给出 ID,你可以通过 http://localhost:37777/api/observation/{id} 或 Web Viewer 看到原始记录是什么。
这套"可追溯"的设计挺好。之前不少类似工具的问题是,模型拿了一段历史上下文做判断,但你不知道它拿的是啥,想核对也核对不了。claude-mem 这里直接给 ID + Viewer,透明度高很多。
中文模式是内置的
~/.claude-mem/settings.json 里改一行:
{
"CLAUDE_MEM_MODE": "code--zh"
}
改完重启 Claude Code,生成的观察摘要就会变成中文。官方说明里写得很清楚:code--zh 是内置模式,不需要额外装包。目前官方支持的语言有:
| Mode | 说明 |
|---|---|
code |
默认英文 |
code--zh |
简体中文 |
code--ja |
日文 |
其他语言按 code--[lang] 的格式,lang 是 ISO 639-1 代码。
Beta 通道:Endless Mode
Beta 通道里有个实验性功能叫 Endless Mode,官方描述是"仿生记忆架构,专门为超长会话设计"。听起来像是在模拟大脑的层次化记忆(短期/长期/巩固)。
我没长期用过,就不知道了。想尝鲜的在 Web Viewer 里 Settings 页切 Beta 版本就行,随时能切回稳定版。
系统要求和注意事项
硬性要求就几条:
Node.js18+- 支持插件的
Claude Code版本 Bun作为运行时和进程管理器,没装会自动装uv(Python 包管理器),向量检索用的,也是自动装SQLite 3,自带
Windows 用户如果碰到 npm : The term 'npm' is not recognized,先检查 Node.js 是否装了并加到了 PATH,重启终端。
支持哪些客户端
安装脚本的 --ide 参数目前官方列出来的:
- Claude Code(默认)
- Gemini CLI(自动识别
~/.gemini) - OpenCode
- OpenClaw 网关
也就是主流的几个 CLI 形态的 AI 编码客户端都覆盖到了。Claude Desktop 这边有专门的 Claude Desktop Skill,可以从桌面端对话里搜你的项目记忆。
配置在哪
所有配置都在 ~/.claude-mem/settings.json 里,第一次运行时会自动生成带默认值的版本。能配的项包括 AI 模型、Worker 端口、数据目录、日志级别、上下文注入规则。细项看官方的配置文档。
遇到问题怎么办
如果用的过程中哪里不对劲,直接在 Claude Code 里把问题描述给它——claude-mem 里带了一个 troubleshoot skill,会自动诊断并给出修复建议。
要提 bug 的话:
cd ~/.claude/plugins/marketplaces/thedotmack
npm run bug-report
这个命令会自动收集日志和环境信息,生成一份完整的 bug 报告模板。
适合谁用
- 长期维护一个或多个项目的独立开发者,频繁在 Claude Code 里开新会话
- 做 AI 编码工具流评测的人,想看生命周期钩子、MCP 工具、向量检索三者怎么组合出跨会话记忆
- 已经在用 Gemini CLI 或 OpenCode,想给它们补一个本地记忆层的
- 团队里有人想在 OpenClaw 网关上统一做记忆管理的
如果你只是偶尔开 Claude Code 改一两行代码,或者项目很小每次都能手动喂一遍上下文,这个东西对你价值不大。它最大化收益的场景是项目够大、会话够多、上下文够碎。